
音声・テキスト変換AIシステム
-
facebook SeamlessM4TSeamlessM4Tは、スピーチ(speech)およびテキストを多言語間で相互に変換するサービスである。下記の変換サービスをWEBページで対話的に実行することができる。
- Speech-to-Speech (S2ST)
- Speech-to-Text(S2TT)
- Text-to-Speech (T2ST)
- Text-to-Text(T2ST)
画像生成AIシステム – text to picture
動画変換生成AIシステム – video to video
シームレスな多言語への音声翻訳を実現するMetaのSeamlessM4T v2のデモ。英語、スペイン語、フランス語、ドイツ語間での音声翻訳が可能である。
SeamlessM4Tは、https://github.com/facebookresearch/seamless_communicationによれば、下記のようなサービスである。
SeamlessM4T is our foundational all-in-one Massively Multilingual and Multimodal Machine Translation model delivering high-quality translation for speech and text in nearly 100 languages.
同サービスは、下記の5つの機能を組み合わせることで実現されている。
Speech-to-speech translation (S2ST)
Speech-to-text translation (S2TT)
Text-to-speech translation (T2ST)
Text-to-text translation (T2TT)
Automatic speech recognition (ASR)
Speech-to-text translation (S2TT)
Text-to-speech translation (T2ST)
Text-to-text translation (T2TT)
Automatic speech recognition (ASR)
音声生成AIシステム ー text to speech
音声認識テキスト生成AIシステム ー speech to text (video to text)
テキスト生成AIシステム – text to text
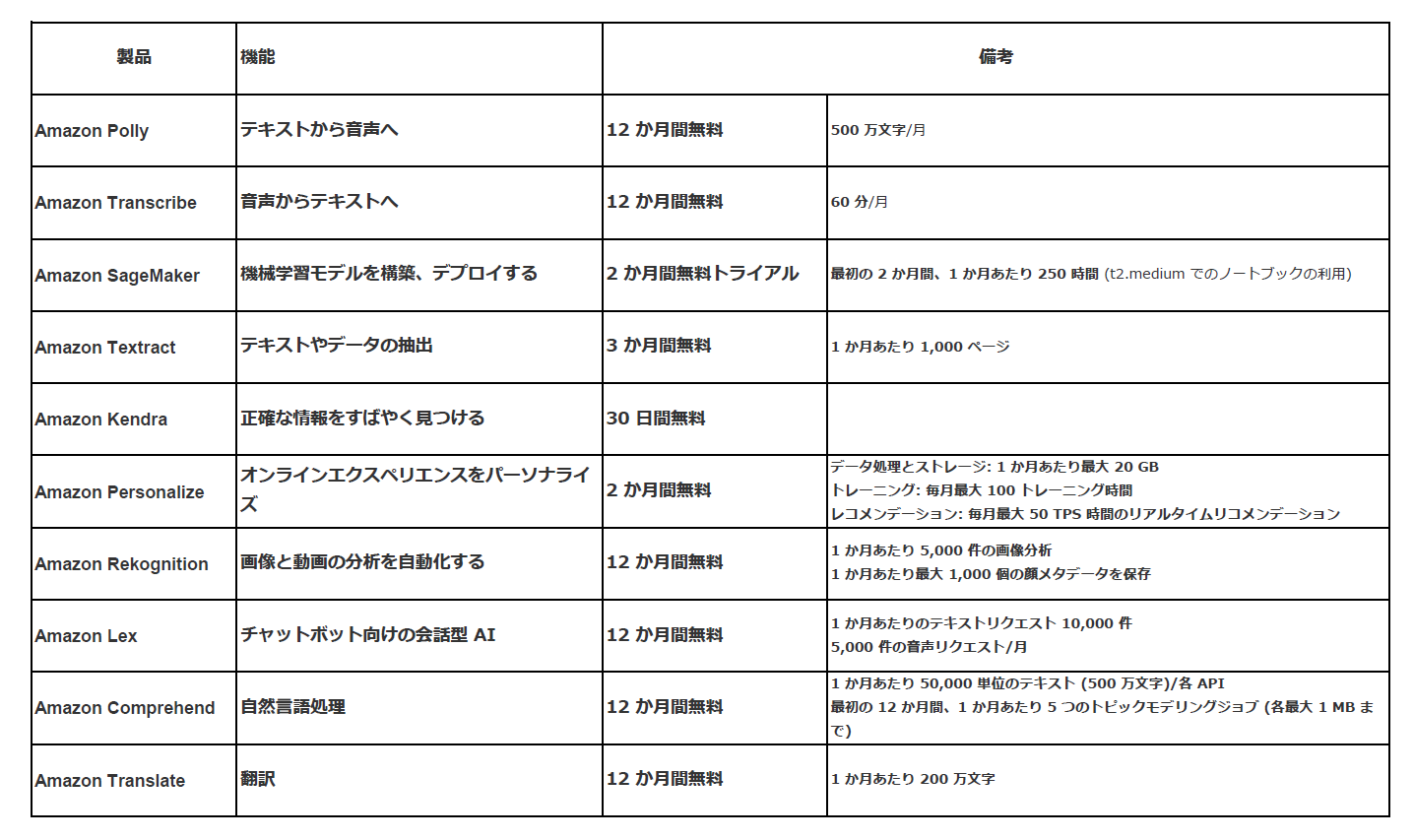
クラウドで機械学習アプリケーションを構築、デプロイ、実行するためのサービスと無料利用枠ご紹介
AWS は、幅広い機械学習サービスとサポートクラウドインフラストラクチャを提供し、すべてのデベロッパー、データサイエンティスト、およびエキスパートに機械学習を提供している。AWS は、Gartner クラウド人工知能デベロッパーサービスのマジッククアドラントリーダーに選ばれ、何万人もの顧客が機械学習の導入を加速するよう支援している。
AWS は、幅広い機械学習サービスとサポートクラウドインフラストラクチャを提供し、すべてのデベロッパー、データサイエンティスト、およびエキスパートに機械学習を提供している。AWS は、Gartner クラウド人工知能デベロッパーサービスのマジッククアドラントリーダーに選ばれ、何万人もの顧客が機械学習の導入を加速するよう支援している。
- テキストから音声へ
- 音声からテキストへ
- 機械学習 — 機械学習モデルを迅速に構築、トレーニング、デプロイします。
- 機械翻訳
生成AIシステム・チェッカー